
AlphaVM Benchmarks
The following host systems were used to benchmark AlphaVM:
- T1 is an Intel i7-960 @ 3.2GHz, Windows 7, hyper-threading on.
- T2 is an HP Proliant DL320E Gen8 v2 with Intel E3-1240v3 @ 3.4GHz, Windows Server 2012R2, hyper-threading on.
- T3 is an Intel E3-1270v3 @ 3.5GHz, Windows Server 2012R2, hyper-threading on.
In the benchmarks below the default AlphaVM configuration is as follows: 1CPU, 256MB RAM, JIT2, 2048 JIT pages, idle disabled, experimental features disabled. This configuration corresponds to one of our reference systems DS10 6/667,256MB RAM.
OpenSSL benchmarks
OpenSSL uses CPU intensive encoding and encryption algorithms. It has built-in commands to measure performance.
The benchmark was measured on Tru64 5.1b. The results are also relevant
for OpenVMS, because the algorithms do not depends much on the
operating system.
The benchmarks can be run by the following commands:
openssl speed md5
openssl speed rsa
Higher results represent better performance.
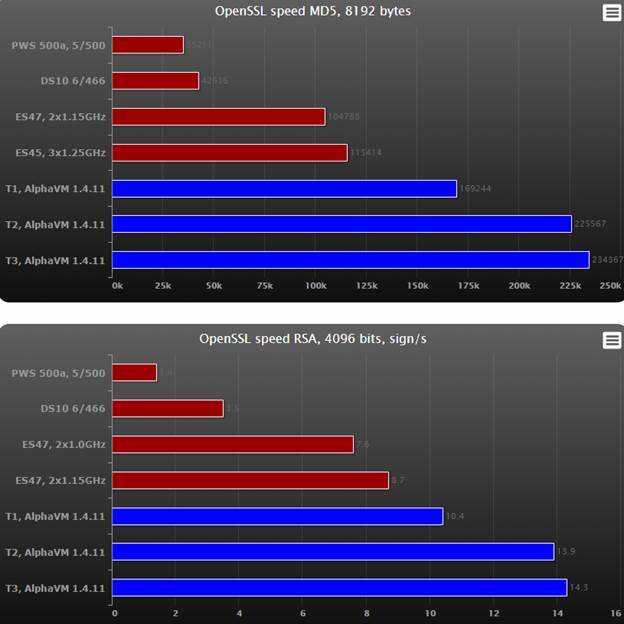
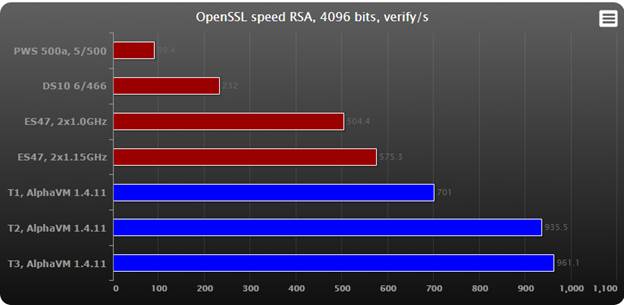
Observations:
- AlphaVM leaves even the fastest Alpha CPU far behind.
NBench
NBench measures performance of several widely used CPU-intensive
algorithms. In the end it computes 3 numbers: Memory index, Integer
index and Floating Point index.
We have run the tests on Tru64
5.1b. It should be noted that CPU benchmarks behaviour does not depend
much on the operating system. Thus, the benchmark is also
representative for OpenVMS usage.
The benchmark can be found here. It has been compiled on a freshly installed Tru64 5.1b-4. To compile it we edited the makefile to enable DEC C compiler:
# for DEC Unix using cc you can try
CC = cc
CFLAGS = -O3
LINKFLAGS = -s -non_shared
The compiler reports itself as
# cc -V
Compaq C V6.5-011 on Compaq Tru64 UNIX V5.1B (Rev. 2650)
Compiler Driver V6.5-003 (sys) cc Driver.
Higher results represent better performance.
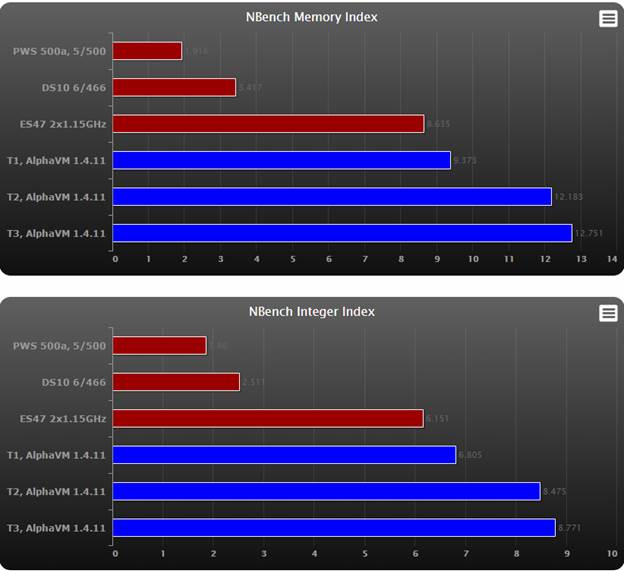
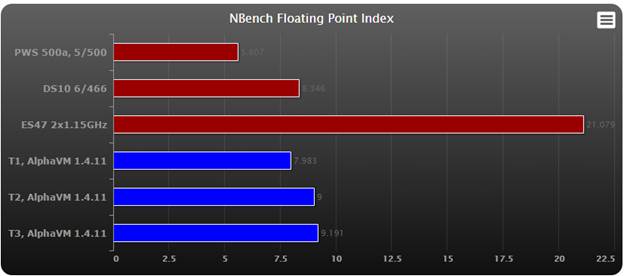
Observations:
- AlphaVM memory and integer performance is on par with the fastest Alpha CPU.
- AlphaVM is currently not so fast with Floating Point. We are working on an improvement of FP performance.
Pi computation
This
benchmark measures time needed to compute PI with the precision of
40000 digits. It was introduced by Migration Specialties to benchmark
their emulator and real Alpha systems.
The program to compute PI is
available in the macro assember examples on OpenVMS. It is located in
sys$examples:macro64$pi.m64. Compile and run it as follows:
$ macro/alpha_axp/object=pi sys$examples:macro64$pi
$ link pi
$ run pi
The executable compiled for 7.3-2 can be found here: pi.exe. This executable also run on other version of OpenVMS, like 8.4. The DCL script to measure time is as follows:
$ t = f$cvtime(f$time(),,"secondofyear")
$ run pi
40000
$ t = f$cvtime(f$time(),,"secondofyear") - t
$ write sys$output "Computed in ''t' sec"
In the chart lower times represent better performance.
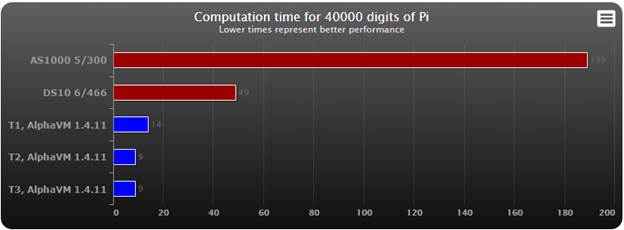
Observations:
- AlphaVM leaves not chance to real Alpha.
VUPs
VUP stands for VAX Unit of Performance. It is an OpenVMS DCL script
originally designed to measure performance of VAX systems.
The benchmark involves a lot of OpenVMS system activity like mode and
context switches. In this sense it is different from the usual CPU
benchmarks. The result includes not only the plain computational speed,
but also the performance of the system activity.
Unfortunately the test has a number of drawbacks. It cannot be considered as an exact measurement.
- Different boots of the OS produce substantially different results. The difference can be 5% or perhaps more (on real Alpha systems).
- The test is even less accurate in SMP environment.
- The test produces very different results on different versions of OpenVMS.
Nevertheless, this benchmark is very popular in the OpenVMS world.
The original DCL procedure was sometimes hanging in a infinite loop on
fast CPUs. It has been improved by Volker Halle. We use this improved
procedure vups_com.txt.
In the chart higher results represent better performance.
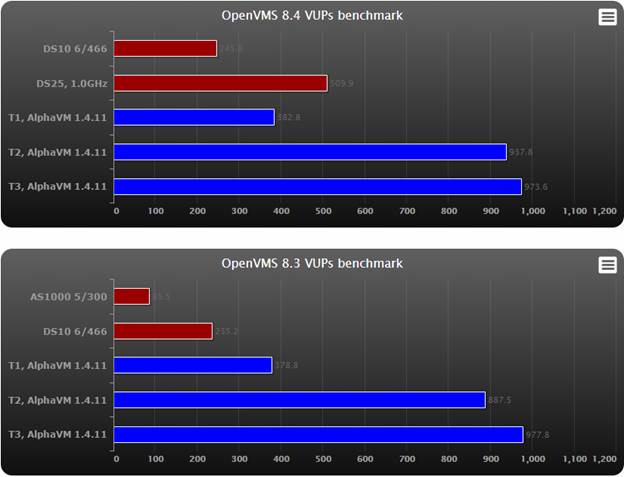
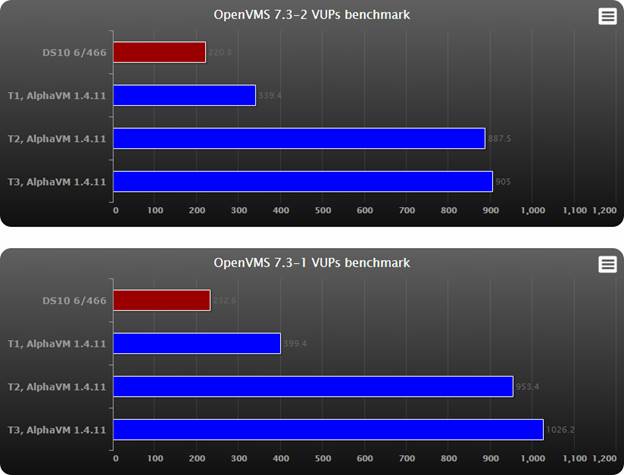
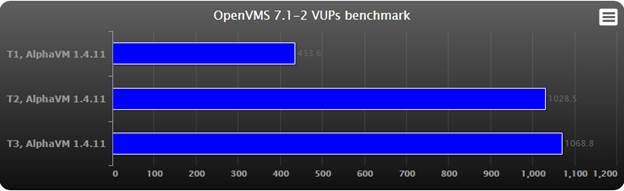
Observations:
- On a new CPU AlphaVM is faster than any Alpha system.
- AlphaVM performance on newer Intel CPUs is much faster than on the older CPUs, even if the clock speed difference is not that big.
Diskblock - OpenVMS Disk IO benchmark
Diskblock is a free OpenVMS tool for low-level disk IO operation. It
has a command to benchmark disk IO performance. We have used the
version 6.2 under OpenVMS 8.4. It can be downloaded from here.
Install the tool as follows. Download the files (diskblock062.a,
diskblock062.b, ...) to your disk, say to dka0:[here_is_the_kit]. Then
run the command:
$ @sys$update:vmsinstal diskblock dka0:[here_is_the_kit]
The benchmark has been run as follows
$ mc diskblock
select dka0: /over
test /iosize=1 /queue=20 /readpercent=100 /duration=300
The benchmark has been run on the system disk. Thus, so far only the
read of system disk has been benchmarked. This scenario can be
reproduced on any system with just the boot disk. The throughput was
measured for several IO sizes.
AlphaVM has been configured with file caching disabled. File caching
improves performance. When file caching is enabled, the throughput
sometimes reaches the gigabytes per second range. However, the result
is highly dependent on the history of the previous access to the disk
image. That makes it harder to get stable results. The benchmark with
the caching enabled will be added later.
The idle mode has been enabled.
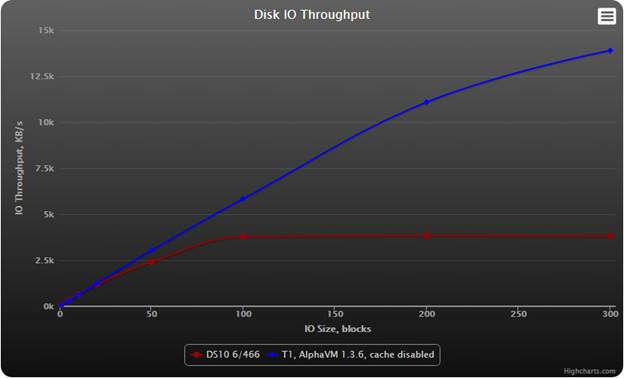
AlphaVM is somewhat slower that DS10 with small IO sizes, but it is
much faster with the larger sizes, even with the caching disabled.